


Much ado about data – what brands could learn from Shakespeare and machine learning:

April 23rd has come to be known as Shakespeare Day in the UK, and this Monday marks 402 years since the bard booted the bucket. Here at Pull we’re fascinated with how technology impacts brand and marketing, and it was while scrambling around for some relevant content, we got thinking: If Shakespeare were alive today, what might technology be able to tell him about his writing?
Now, it’s unlikely ol’ Bill would have been able to condense the tragedy and heartbreak of Romeo and Juliet into a mere 140 character tweet (though we’d love to see him try), but this did remind us of a striking analysis shown to us by Microsoft’s AI guru, Phil Harvey, on a recent visit.
Phil, a Cloud Solutions Architect for Data & AI, decided to analyse five of Shakespeare’s plays using Microsoft Azure’s Cognitive Services; namely their Text Analytics. Text Analytics would allow Phil to understand and map the overall sentiment of each of these plays, as well as emotions experienced at key plot points. So, why Shakespeare?
First off, this had to be done with a well-known body of text. Also, the plays were written in older English - typically, sentiment analysis tools have struggled with sarcasm or slang, so this presented a nice challenge. Lastly, from scholars and historians to spotty sixteen-year-olds, Shakespeare’s works are amongst the most analysed and therefore most familiar, so where better to start?
“Shakespeare didn’t write plays for data processing”.
While not without its challenges - devising a way to tidy up formatting inconsistencies within 120,000 lines of text for example – feedback from English scholars was encouraging, and the data analysis was able to accurately capture the emotions felt by the characters as the plots unfold.
In the example of Macbeth below, you can see how the chart manages to plot suspense and emotional narrative.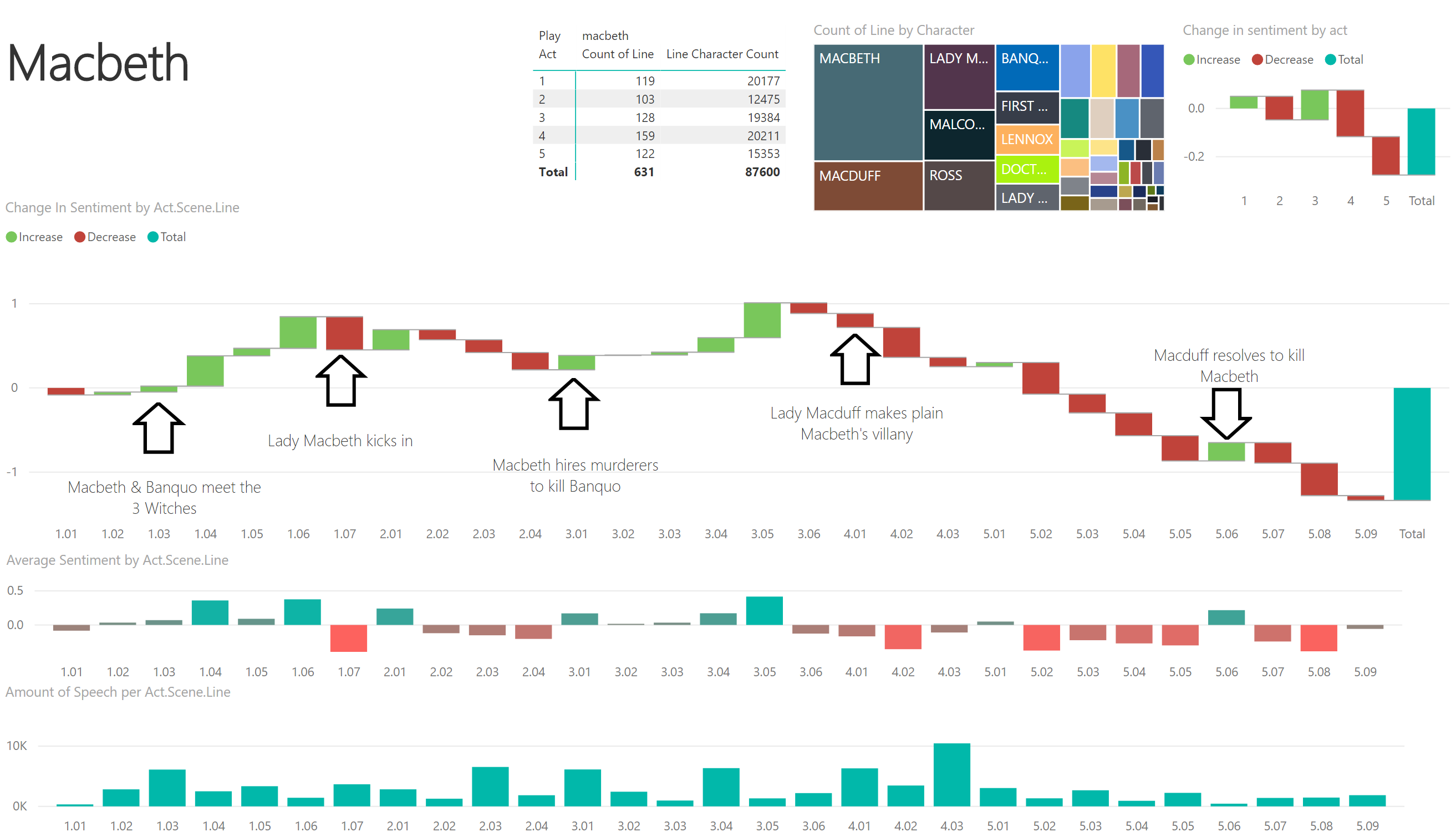
While the mood starts darkly and basically ends darker still – which wouldn’t really surprise anyone only vaguely familiar with the bloody tale, some might be surprised to see so much positive sentiment apparent. This probably illustrates both the strength and weakness of this kind of analysis: The ‘positive’ sentiment in fact reflects the ambition and plotting of Macbeth and his wife. It is impressive that the analysis is able to pick this up. However, what if – as is the case here – the positive sentiment is in fact felt by bad people plotting bad deeds? Some more learning for the software perhaps?
So, what does this sort of analysis mean for brands, and can it be of any use?
There are already a fair number of social media listening tools that offer to monitor customer sentiment, but these are rarely sophisticated enough to detect sarcasm, slang or in some cases even decipher emojis. Work like Phil’s showcase what more could be achieved.
At this point, it is also worth considering the work of Franco Moretti, an Italian literary scholar and prominent figure in the field of Digital Humanities. Moretti argues that, contrary to the traditional ‘close reading’ of a single text or genre canon, in order to truly understand literature and the themes at work you need to analyse thousands of texts. Even then you may not have the full picture.
Known as Distant Reading, Moretti contends that this form of analysis highlights “the regularity of the literary field. Its patterns, its slowness”. To understand, we must take a step back and allow the analysis to show us the forest rather than the trees.
While this ruffled some feathers amongst traditional literary scholars, brands – particularly those with products to shift and customers to shift them to – could learn a thing or two from this approach.
For example, Moretti used his computer to analyse the titles of some 7,000 British novels published between 1740 and 1850. In 1740, the average title length was 25 words. In 1850? Just 8. This information could be the spring board for a look at what changed during this time period to result in this character-cull. Perhaps this can give us some clues about where brands should be looking to utilize sentiment analysis.
It’s not just about their sentiment, but trends and habits. For example, are people engaging with fewer words on the company’s social media channels? Perhaps there has been a shift in tone/content or positioning and people now feel less engaged with a brand? Are there fewer mentions of a particular product than there used to be? (In the study above, Moretti himself was able to track the rise in popularity of certain genres, before they died out completely).
“I’ll call for pen and ink Twitter, and write my mind.”
So, there you have it. From detecting good sentiments from bad people about doing bad things in Shakespeare to social media, and a heap of unconventional data analysis. Happy Shakespeare Day! Next week, we use Microsoft Azure’s FACE API to find out what the Mona Lisa was really thinking…
We are currently working closely with Microsoft on using similar technologies to analyse some of our own client data sets in a brand and research focused piece. Watch this space for exciting announcements in this area soon.
Posted 20 April 2018 by Ben Waterhouse